
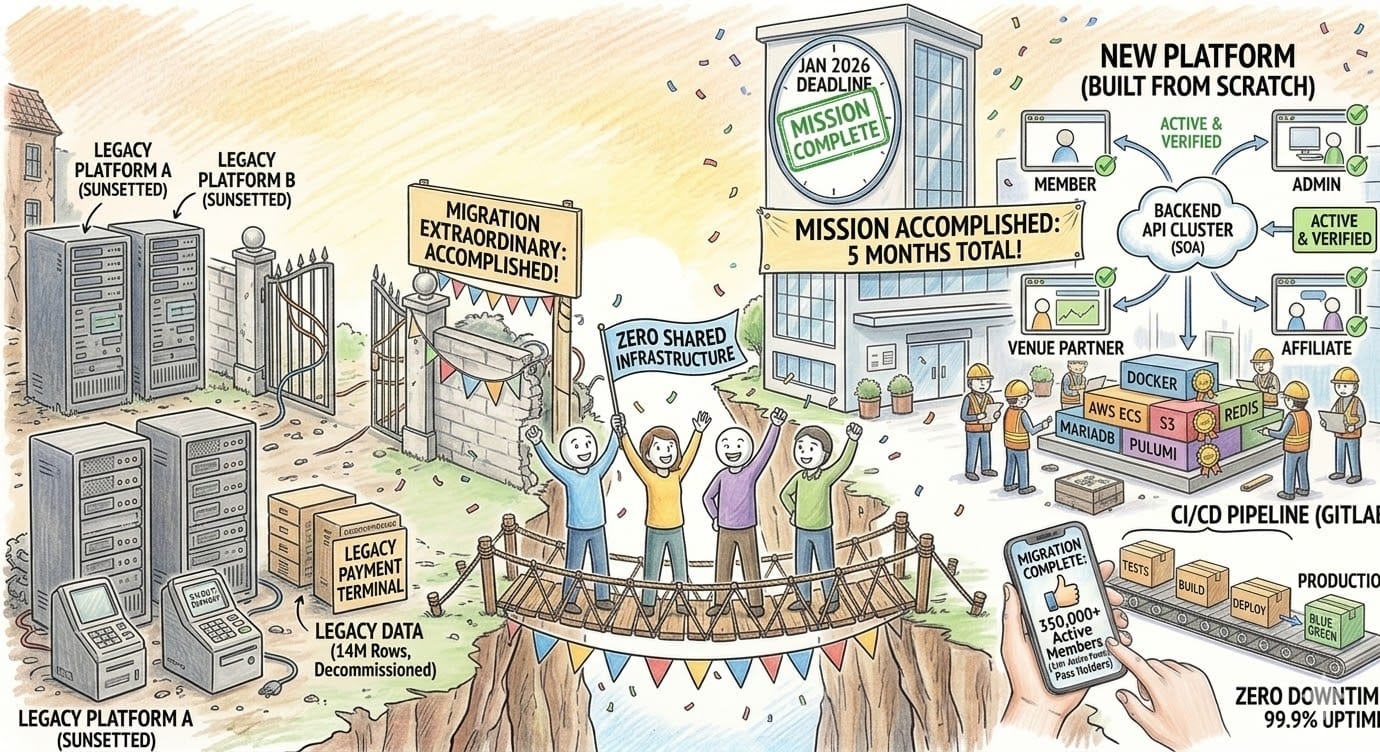
The long story of combining two companies through an acquisition, from a technical perspective, in a little over 5 months.
TLDR
2 completely different companies, were combined into 1. We sunset 2 legacy platforms, migrated over 350k+ active members (representing over 1M active family pass holders), migrating 20M+ rows of data, 0 shared infrastructure, different payment systems, and needing to be able to serve ~2M+ requests daily. We built the replacement from scratch. 5 months. 4 engineers.
I've built and been a part of systems with a significant volume of users, revenue, and financial transactions. I've launched new products, co-founded and seen my own through an exit, and I tried to retire. I've sunset legacy systems, helped run massive data warehouse transitions, worked on a product with over 30 microservices, and helped scale engineering teams to 70+.
The Clock Was Already Running

I came onboard sometime in August 2025. Earlier in the year, the business had identified the ideal launch of the new, combined business to be sometime around January 2026, maybe early February 2026. Five to six months to combine two companies with completely different products, and services.
DIFFERENT, EVERYTHING!
Different payment systems.
Different authentication services.
Different mobile applications.
Different database schemas and engines.
Different CI/CD pipelines.
Different technologies.
Different data shapes.
One platform was a monolith with a custom in-house CMS with ECMAScript. The other had separate frontends in Vue and Nuxt for different pieces, and an older framework I haven't touched since ~2008.
5 months. 2 platforms. No shared foundation. And over 350k members with over 1M family members who needed the transition to be invisible so the ~7M ongoing smiles could continue! 😄 🎉
The Plan That Didn't Survive Contact
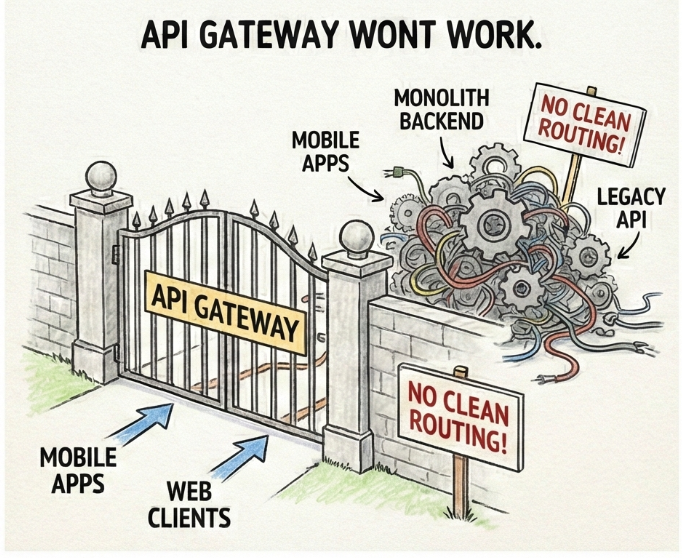
My original plan was to start with an API Gateway. I presented this concept to Kyle and Andy, when brainstorming outloud how I would approach this, without knowing anything about the existing codebase and infrastructure. I also drew this on a white board in a presentation, explaining my initial ideas around the objective.
Point all mobile apps and frontend clients (multiple browser clients, and 3 mobile applications (react-native, swift and kotlin) at a single ingress, let the gateway handle routing to backend services. This would buy us control and then we could slowly build new services behind the scenes, reroute requests from old to new, and nobody notices the swap. Then we could build the new clients, and replace the old.
I've done this before many times whether it was for sunsetting a legacy service, or a replatform. It works and is great! You can then set up an ACL microservice, Auth sidecar, BFF… the list goes on.
But, it wouldn’t work here, not as the initial direction. I quickly realized this when I got access to the code and infrastructure.
An API Gateway assumes you have backend services to route to. We didn't. One platform was a true monolith, with frontend and backend welded together in the same codebase, business logic buried in view layers, PHP and JavaScript interleaved in ways that made separation surgery. The other platform technically had an API, but only for one corner of the product. Everything else ran through a separate monolith that didn't talk to the first one. Duplicate data, duplicate logic, zero shared infrastructure.
To make the API gateway work, we'd have had to trace every embedded route through PHP frontend templates, JavaScript bundles, legacy handlers and then modify them to point at the gateway instead of wherever they were hardcoded to go. We'd be doing the hard work anyway, just with extra steps and no clean foundation underneath.
So we stopped. Switched to maintenance mode on both platforms and started building everything new: infrastructure, backend API services, frontend clients, mobile apps.
NEW, EVERYTHING.
It sounds daring. It was the only move that made sense. Stitching two systems together would take just as long and leave us owning the combined debt of both. At least this way, we'd own something we could maintain.
Learning While Building
The timeline didn't force us to cut scope. It forced us to learn and build at the same time.
We had to understand two businesses: their logic, their edge cases, their "why does it work this way" quirks that weren't documented, as well as completely learn different nomenclatures. Then take this knowledge and figure out how to make it work in a unified system.
What we inherited from one platform's database alone:
- Over 200 tables
- 0 foreign keys
- Over 1,100 indexes (about 6 per table)
- Over 90 tables with more than 10 columns
No foreign keys meant relationships lived in application code logic. Every migration script would have to reconstruct what the schema should have enforced but didn't. Plus this particular platform was a custom CMS built on top of a framework, using very little of the framework itself, adding more confusion to our lack of knowledge.
The Foundation
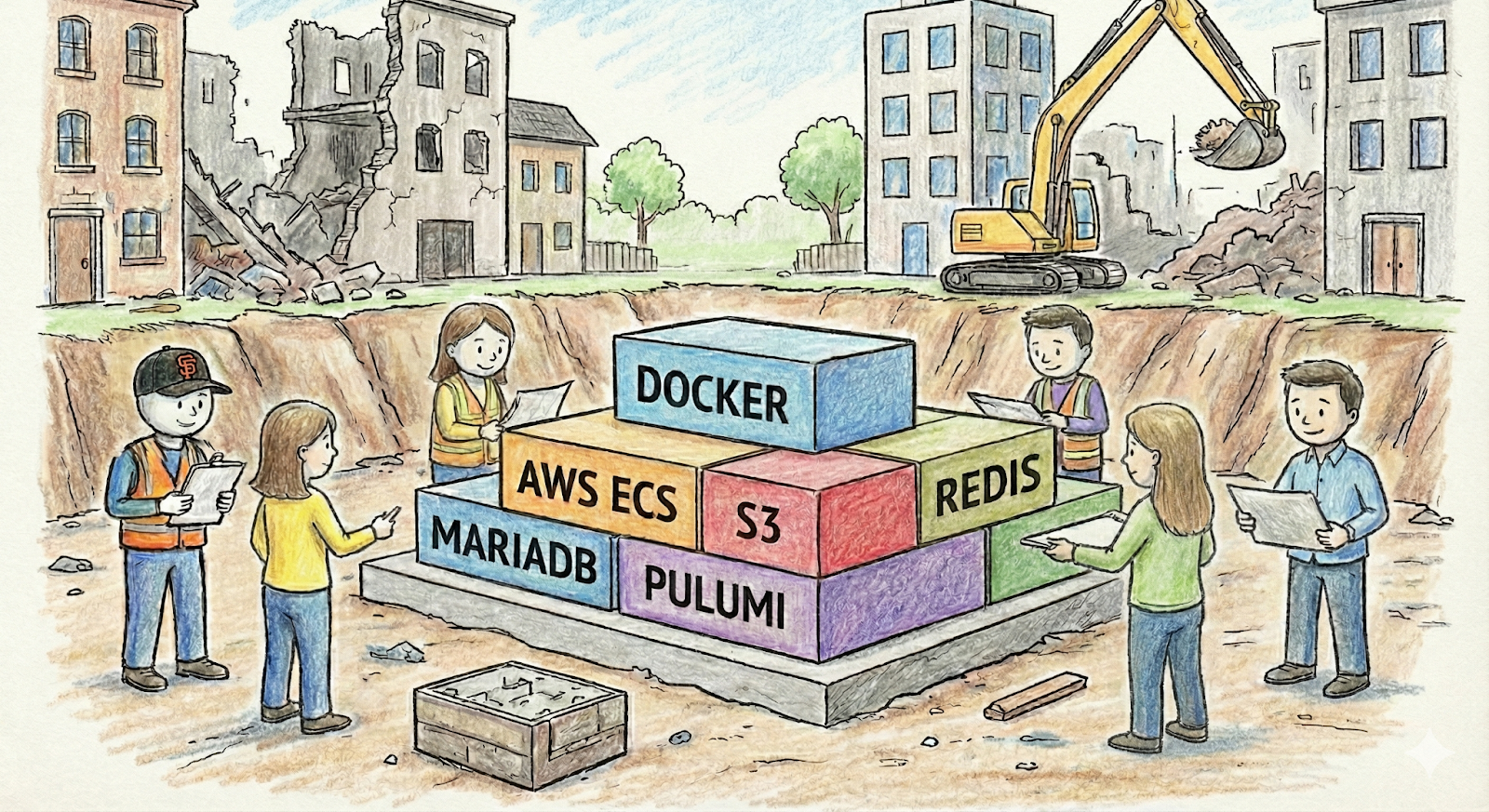
We started with the backend API cluster.
Docker with NGINX, designed so that our local environments would mirror production exactly: what runs in docker-compose locally, the containers in this cluster map directly into AWS ECS: containers orchestrated behind an ALB, RDS for persistence, Redis for caching, S3 for object storage, all isolated within private subnets.
Pulumi handles the IAC keeping this infrastructure simple to expound upon across as many environments as we needed: one AWS account per environment (staging and prod), with a management account overseeing the family.
The backend API follows SOA with a modular approach. We have an application layer handling routing, service layers containing business logic, repository layers abstracting a LOT of data access, and of course this is modular in order to contain domain concerns separated. This API is our central nervous system, hence why we started here, as our web clients, mobile apps, event systems, queue handlers, internal dashboards pulling through Fivetran into BigQuery… everything routes through here.
Authentication lives outside the API entirely. JWT-based auth through Auth0, with dedicated tenant environments per stage. No auth sidecar bolted onto a gateway (which I prefer). We went with this isolation of an auth service, because we have 350k+ users who we need to migrate seamlessly from two completely different authentication systems, plus we're enabling social logins. We have a lot of hooks and helpers we control for various environments and apps.
For the database: MariaDB. Spatial queries are minimal, JSON storage needs are simple, read scale is massive, so Postgres was not deemed as ideal. MariaDB's built-in replication handles that without complexity we don't need yet and I love it. Easy.
The core AWS infrastructure sits behind ALBs, with Cloudfront and WAF layers, accessible only through registered ECS services. Target groups manage all of our configured auto-scaling; private endpoints keep traffic off the public internet. Want to access a container directly, an RDS cluster, or other service directly? Bastions baby!
CI/CD
We went with Gitlab for CI/CD as this has better pipelines than Github's hot garbage, Circle CI is overrated, and AWS Code Pipeline is too clunky (my opinion and I’m always right so…). We have six GitLab runners - three per environment, which handle the full pipeline: building images, running data migrations, deploying ECS tasks and services, and of course the final and best stage: slack notifications that the build completed or failed 🎊
With this pipeline, we setup blue-green deployment that keeps releases at zero downtime: new tasks spin up and health-check before traffic cuts over, old tasks drain gracefully from their services. If something fails, rollback is just pointing back to the previous target group.
We deploy to staging for internal validation of locally tested fixes and changes (a quasi Dev/UAT). From there, a release is cut and to production it goes.
Four Portals, One API
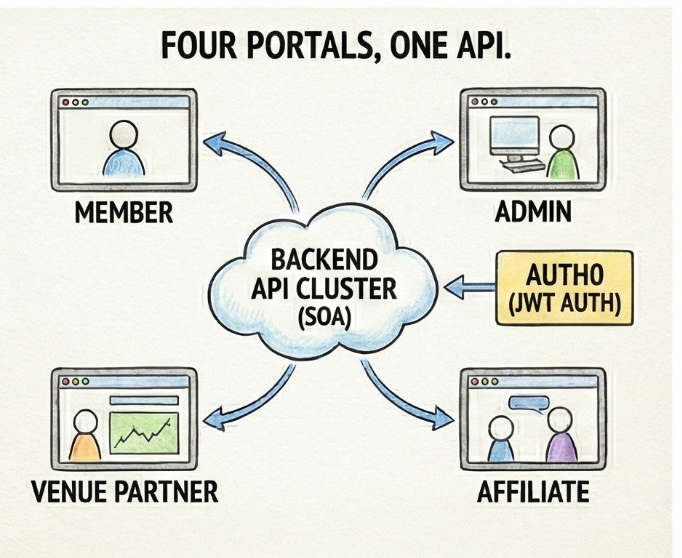
Next, we built four separate frontend portals:
- Admin Portal – internal operations, full system access
- Member Portal – the over 350k users buying passes, managing over 3M family members, redeeming codes
- Venue Partner Portal – locations managing their own redemptions and inventory
- Affiliate Portal – partners with visibility into their referral network
We decided not to have this isolated through subdomains and individual frontend instances, given that these will share the same frontend components underneath. Sure, we could go with a private NPM route for sharing, been there done that, but it was added complexity deemed unnecessary. And yes, a lerna monorepo would work, I've been there and done that, but in this case, also isn't an option.
Different capabilities surfaced based on roles and permissions. Each portal had to feel like its own product while sharing authentication, business logic, and data through a single source of truth.
We kept this to a single frontend leveraging polymorphic roles and permissions with the backend. Typescript, React, Tanstack Query and TanStack Router are the best.
Mobile First - That's Where Members Are
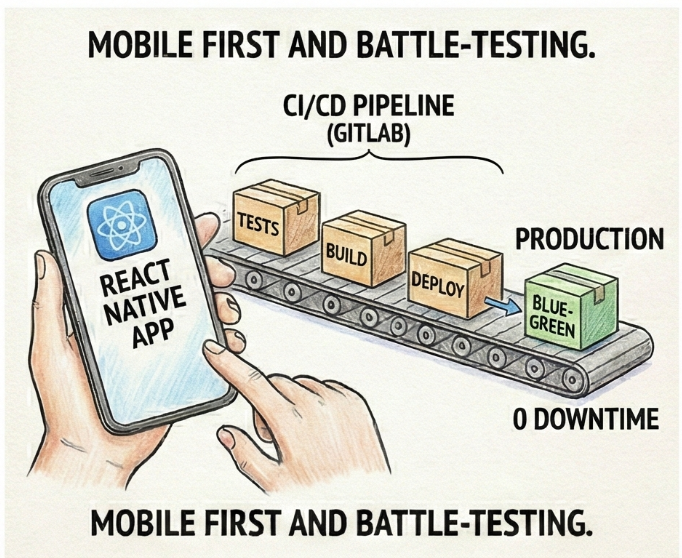
The majority of our ~350k+ members actually live in the mobile application.
Between the 2 businesses, there are 3 different mobile codebases: 1 React Native, and the other platform has native applications in Swift and Kotlin. We couldn't borrow any logic from any of these, and shifted them into maintenance mode also.
We started fresh with React Native and Expo, giving us a single codebase for iOS and Android. Plus, any opportunity to write more typescript, I jump on. Fastlane handled signing and deployment automation locally as well as in a container environment (yup!).
We handed this off to business to be begin testing around November, highlighting our first major milestone accomplishment.
Every test cycle hit the API throttling.
Every auth flow exercised the security layer.
Every data operation validated our models and relationships.
Every build pushed through the CI/CD pipeline.
Every release went through the approval process.
By the time mobile was stable, we'd battle-tested infrastructure we wouldn't have caught with unit tests or staging environments or web portals alone. The app was the product. The testing was the audit.
Web Portals
Once mobile was solid, we moved back to the web portals (we set up the infrastructure and baseline architecture pillars for this in the beginning). Member, Admin, Venue Partner, Affiliate. The architecture was proven and the patterns were established. These builds moved faster because the foundation was no longer theoretical anymore!
With these four portals to build, we focused on the Member portal first.
Not because it was the simplest. Because it touched everything the mobile app did. Purchasing. Redemptions. Family invites. Subscription management. The most complex business logic.
The Admin, Venue Partner, and Affiliate portals could come after. They had complexity of their own, but they were variations on access and visibility. Member was the proving ground.
Data Migration
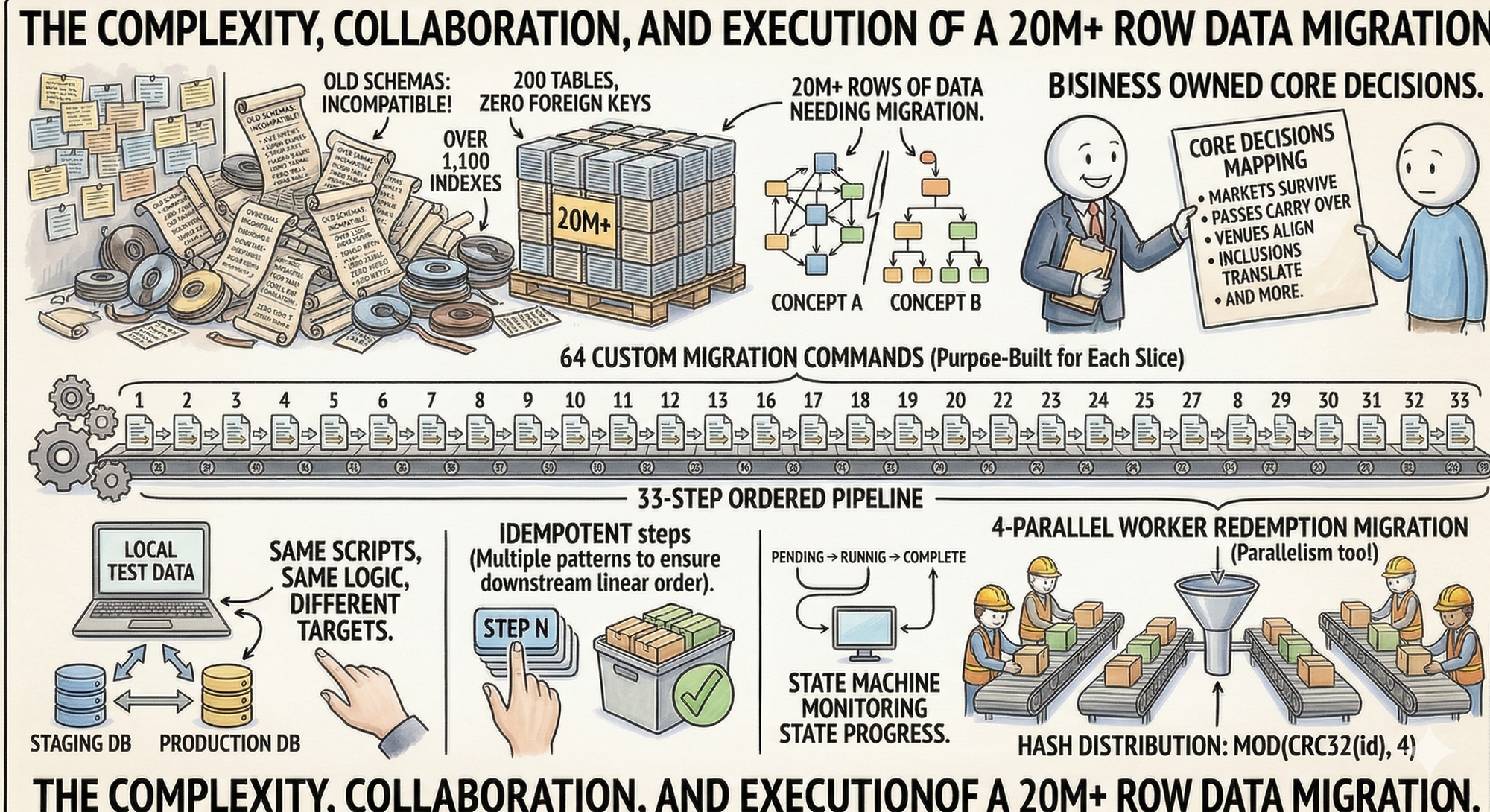
200 tables. 0 foreign keys. Over 1,100 indexes. Two completely different schemas representing the same business concepts in incompatible ways. Over 20m rows of data needing to be migrated. Trying to figure out how to take this data, and merge it with the other platform into a new schema was fun.
Thankfully, business owned the core mapping decisions: which markets survive, which passes carry over, how venues align, what inclusions translate to what, and more.
We took those decisions and built the how. 64 custom migration commands organized into a 33-step ordered pipeline, each one purpose-built to move a specific slice of the data. Custom migration scripts designed to run locally against test data, then swap connection strings and execute against real data in any environment. Same scripts, same logic, different targets. We could validate a migration approach on our machines, then run it against staging, then production.
Every migration step is idempotent so we can run any command twice, or ten times, and still get the same result. We achieved this through multiple patterns depending on the data shape. We also built a state machine to help monitor the progress of states to ensure downstream steps completed in the right linear order.
The whole data migration system was built for parallelism too, distributing ingestion across workers using MOD(CRC32(id), workers) for even hash-based distribution. Each worker operated on its own partition with no coordination needed and some would run with 4 parallel workers by default but this could also be configured.
One Payment System, 350k+ Users
The two platforms didn't just have different databases. They had different payment systems. One used Nexio. The other used Square. Both had tokenized customer payment methods.
We weren't going to run two payment systems forever. Square was the path forward. That meant migrating 150k+ users' from one system, from Nexio to Square, then mapping them correctly to the user records in the new system.
This wasn't just about enabling future purchases. Historical transactions had to be easily mapped (for future purposes, when needed). Current pass status had to survive the move. A member who bought a year pass in October through the old Nexio system needed to show up in the new platform with that pass intact, their payment method ready, and their history queryable.
The Last Possible Moment
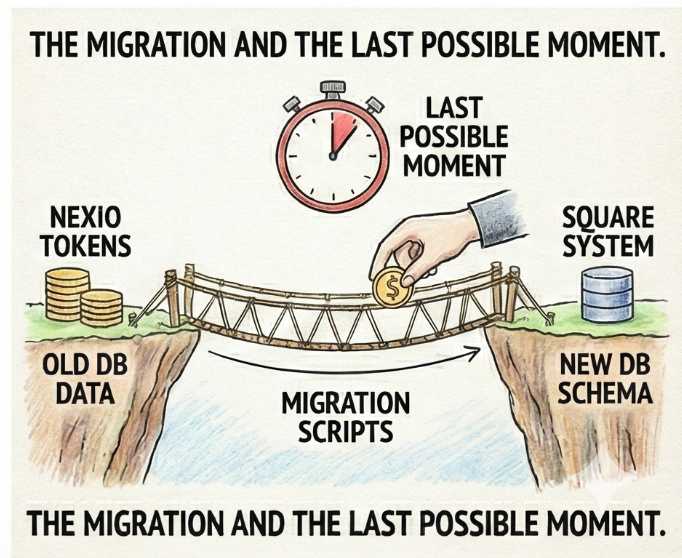
Financial token migration had a catch: it could only happen once.
The moment we pulled tokens from Nexio, the clock stopped. Any new cards added, they wouldn't be available to be transferred, and they'd exist in the old system with no path to the new one.
So we pushed the migration as late as possible. Let the old system keep capturing new payment methods right up until we couldn't wait anymore. The goal was to maximize coverage, and get as many tokens across as we could before cutting over.
It meant the financial migration became one of the final steps, not an early foundation piece. Everything else had to be ready and waiting. Infrastructure, API, portals, mobile app—all staged and tested. Then, at the last responsible moment, we'd pull the tokens, map them to the new user records, and go live.
The Team

Three of us walked in knowing nothing. One engineer held the institutional knowledge of both platforms, and the rest of us leaned on that heavily, while simultaneously building things none of us had built before. When something broke, nobody waited to be told what to do, they went directly to stakeholders, dug into the problem, and came back with answers. We worked in parallel out of necessity, siloed by domain, but never disconnected. 4 people. 5 months.
Without this team, we couldn’t have pulled this off.
And in an era where companies are vibe coding their way into technical debt hell, and calling it a product (50k lines of slopped together hot garbage code), 4 people who actually know what they're doing built something that serves over 350k members. We did this quietly and without announcing it on LinkedIn 14 times a day, or starting a podcast about it.